




機械学習で予測するエロゲ価格変動 (ランダムフォレスト編)
エロゲの中古価格は人間が予測する時代から、
コンピュータが予測する時代へ!
今回は『このエロゲは3ヶ月後に3000円まで値下がりしているだろう』のように、
今まで人間がなんとなく経験則で予測してきたエロゲの中古販売価格を、
コンピュータに予測させてみようということが目的です。
発売30日間のエロゲの中古販売価格情報から、
発売後31日目から90日目までの販売価格の価格変動を予想します。
機械学習には様々なアルゴリズムが存在しますが、
今回はランダムフォレストと呼ばれる機械学習アルゴリズムを使用します。
ざっくり言うと、過去のデータに基づいてたくさんの決定木をつくり、
その決定木を辿っていくことで、どの位の価格になるのかを推定するような感じです。
決定木の一例としては、『発売30日目で4000円以上か?』みたいなものです。
細かいことが知りたい方はググってください。
(・・・というか細かく説明できるほど詳しくないです。)
似たようなところだと、株価をランダムフォレストで予測しているWebサイトや研究が多く存在します。
ランダムフォレストを使用するにあたって、
統計解析向けのプログラミング言語であるR言語を使用します。
統合開発環境としてRStudioを使用しています。
RStudioは非常にインターフェースが使いやすくて、
R言語を使用するハードルをかなり下げてくれているソフトウェアだと思います。
2014年3月から2015年1月までに発売された、
フルプライス帯のエロゲ合計179作品の発売後30日間(+31~90日目)の価格変動を、
学習用データ125作品、パラメータ調整用データ54作品に、ランダムに分けます。
パラメータ調整が終了した後は、
179作品の発売後30日間(+31~90日目)の価格変動全てを学習用データとし、
2015年2月・3月発売作品の発売後30日間の価格変動を予測用データとして使用します。
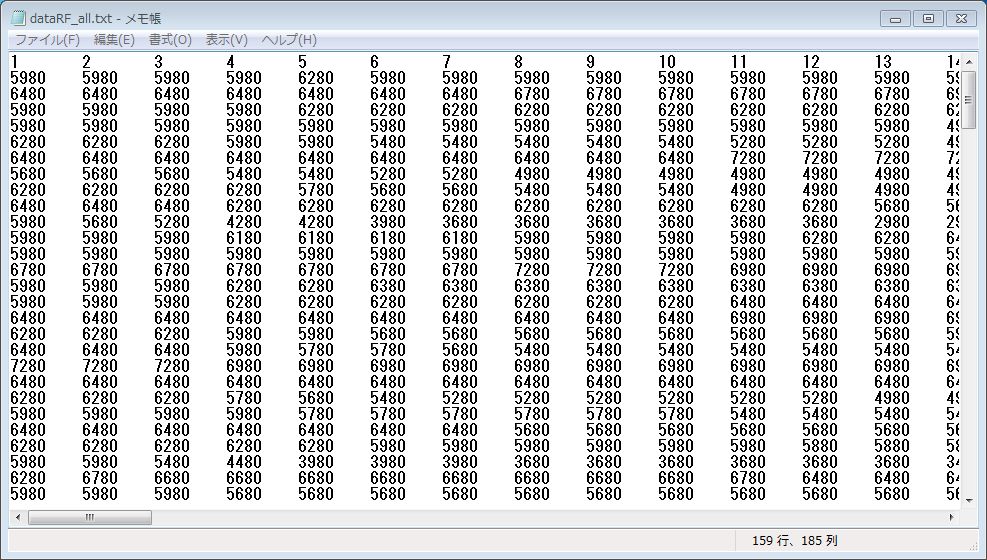
準備1. データファイルの作成
ラベルを1行目、教師用データを2行目から126行目、テスト用データを127行目から180行目、
予測用データを181行目以降に記述したデータファイルを作成します。
準備2. パラメータの調整
長々しくあまり面白くないので省略。予測するところだけ紹介します。
決定木の数は300あたりにすると精度が良さそうだったので、300で予測。
決定木のサイズはデフォルトです。
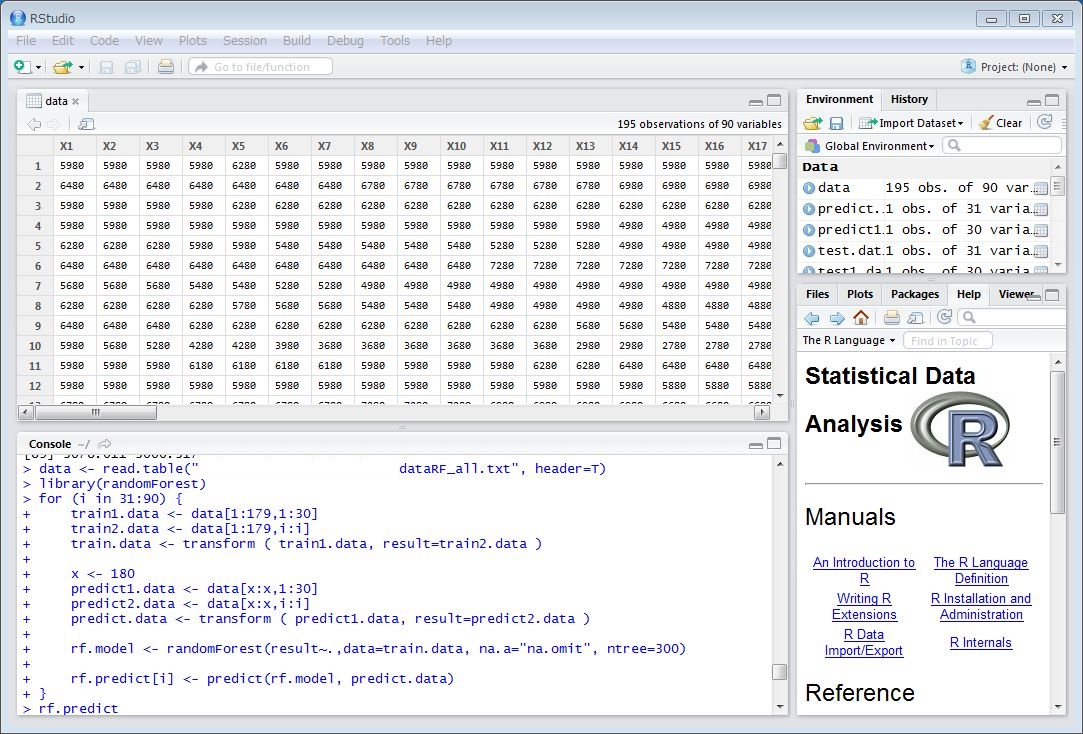
1. データファイルの読み込み
data <- read.table("dataRF.txt", header=T)
2. ランダムフォレストのライブラリの読み込み
library(randomForest)
3. 予測
train1.data <- data[1:179,1:30] #発売後30日間の学習用データ
train2.data <- data[1:179,31:31] #発売後31日目の学習用データ
train.data <- transform ( train1.data, result=train2.data ) #結合
x <- 180 #180番目のエロゲについて予測
predict1.data <- data[x:x,1:30] #発売後30日間の予測用データ
predict2.data <- data[x:x,31:31] #発売後31日目の予測用データ(予測する数値、適当な数字が入っている)
predict.data <- transform ( predict1.data, result=predict2.data ) #結合
rf.model <- randomForest(result~.,data=train.data, na.a="na.omit", ntree=300)
#学習用データに基づきランダムフォレストのモデルを作成(決定木の数は300)
rf.predict <- predict(rf.model, predict.data)
#作成したランダムフォレストのモデルと発売後30日間の予測用データに基づき、31日目の価格を予測
4. 繰り返す
for文で31日目から90日目まで回す。(一番上の画像)
5. 結果の出力
31日目から90日目の予測が出力される。
いきなりですが、予測が外れている例です。
4/1までは良さそうです。しかし、その後予測では下落が続いていますが、
実際は5000円付近で安定しています。
続いて、2月発売で予測が当たっている例です。
少し実際の価格よりは低めですが、変動の動き自体はほぼ完璧です。
今日はわずか73円の誤差です。
続いては3月発売作品の予測です。
30日の直後に大きく値下がりがありましたが、良い感じで予測できています。
ただ、『サノバウィッチ』と似た感じで、今後は下落しすぎな予測な気がします。
最後の例ですが、予測によると今後は緩やかに下落が続き、
6月中には2000円台も視野にという感じですね。
トレーダーでは既に3480円なので、現実味があるかもしれません。
・今回は発売後90日間の販売価格を素性として、ランダムフォレストで機械学習を行いましたが、
買取価格やその他の情報を素性に加えることで精度が向上する可能性があるので、素性の検討をすること。
・パラメータの調整をもう少し細かく行うこと。
・他の機械学習アルゴリズムを試して、どのアルゴリズムがエロゲの価格変動に適しているか比較すること。
・学習データが不足していると思うので、学習データを増やして機械学習を行うこと。
・予測の評価を行うこと。
このあたりが今後の課題として挙げられます。
ランダムフォレストによる機械学習でエロゲの価格変動を予測を行いました。
結果としては、外れていた部分もありますが、概ね良好な結果になったと思います。
私が予測するよりも良い精度かもしれません。
今後余裕があれば普段の更新でも、
機械学習による予測結果も紹介したいと思います。
コンピュータが予測する時代へ!
機械学習とは?
(Wikipediaより引用)
今回は『このエロゲは3ヶ月後に3000円まで値下がりしているだろう』のように、
今まで人間がなんとなく経験則で予測してきたエロゲの中古販売価格を、
コンピュータに予測させてみようということが目的です。
目的
発売30日間のエロゲの中古販売価格情報から、
発売後31日目から90日目までの販売価格の価格変動を予想します。
手段
機械学習には様々なアルゴリズムが存在しますが、
今回はランダムフォレストと呼ばれる機械学習アルゴリズムを使用します。
ランダムフォレストとは?
(Wikipediaより引用)
ざっくり言うと、過去のデータに基づいてたくさんの決定木をつくり、
その決定木を辿っていくことで、どの位の価格になるのかを推定するような感じです。
決定木の一例としては、『発売30日目で4000円以上か?』みたいなものです。
細かいことが知りたい方はググってください。
(・・・というか細かく説明できるほど詳しくないです。)
似たようなところだと、株価をランダムフォレストで予測しているWebサイトや研究が多く存在します。
方法
ランダムフォレストを使用するにあたって、
統計解析向けのプログラミング言語であるR言語を使用します。
統合開発環境としてRStudioを使用しています。
RStudioは非常にインターフェースが使いやすくて、
R言語を使用するハードルをかなり下げてくれているソフトウェアだと思います。
使用するデータ
2014年3月から2015年1月までに発売された、
フルプライス帯のエロゲ合計179作品の発売後30日間(+31~90日目)の価格変動を、
学習用データ125作品、パラメータ調整用データ54作品に、ランダムに分けます。
パラメータ調整が終了した後は、
179作品の発売後30日間(+31~90日目)の価格変動全てを学習用データとし、
2015年2月・3月発売作品の発売後30日間の価格変動を予測用データとして使用します。
手順
準備1. データファイルの作成
ラベルを1行目、教師用データを2行目から126行目、テスト用データを127行目から180行目、
予測用データを181行目以降に記述したデータファイルを作成します。
準備2. パラメータの調整
長々しくあまり面白くないので省略。予測するところだけ紹介します。
決定木の数は300あたりにすると精度が良さそうだったので、300で予測。
決定木のサイズはデフォルトです。
1. データファイルの読み込み
data <- read.table("dataRF.txt", header=T)
2. ランダムフォレストのライブラリの読み込み
library(randomForest)
3. 予測
train1.data <- data[1:179,1:30] #発売後30日間の学習用データ
train2.data <- data[1:179,31:31] #発売後31日目の学習用データ
train.data <- transform ( train1.data, result=train2.data ) #結合
x <- 180 #180番目のエロゲについて予測
predict1.data <- data[x:x,1:30] #発売後30日間の予測用データ
predict2.data <- data[x:x,31:31] #発売後31日目の予測用データ(予測する数値、適当な数字が入っている)
predict.data <- transform ( predict1.data, result=predict2.data ) #結合
rf.model <- randomForest(result~.,data=train.data, na.a="na.omit", ntree=300)
#学習用データに基づきランダムフォレストのモデルを作成(決定木の数は300)
rf.predict <- predict(rf.model, predict.data)
#作成したランダムフォレストのモデルと発売後30日間の予測用データに基づき、31日目の価格を予測
4. 繰り返す
for文で31日目から90日目まで回す。(一番上の画像)
5. 結果の出力
31日目から90日目の予測が出力される。
例1. 『サノバウィッチ』 (ゆずそふと)
いきなりですが、予測が外れている例です。
4/1までは良さそうです。しかし、その後予測では下落が続いていますが、
実際は5000円付近で安定しています。
例2. 『ソレヨリノ前奏詩 豪華版』 (minori)
続いて、2月発売で予測が当たっている例です。
少し実際の価格よりは低めですが、変動の動き自体はほぼ完璧です。
今日はわずか73円の誤差です。
例3. 『花咲ワークスプリング!』 (SAGA PLANETS)
続いては3月発売作品の予測です。
30日の直後に大きく値下がりがありましたが、良い感じで予測できています。
ただ、『サノバウィッチ』と似た感じで、今後は下落しすぎな予測な気がします。
例4. 『ゆきこいめると』 (FrontWing)
最後の例ですが、予測によると今後は緩やかに下落が続き、
6月中には2000円台も視野にという感じですね。
トレーダーでは既に3480円なので、現実味があるかもしれません。
今後の課題
・今回は発売後90日間の販売価格を素性として、ランダムフォレストで機械学習を行いましたが、
買取価格やその他の情報を素性に加えることで精度が向上する可能性があるので、素性の検討をすること。
・パラメータの調整をもう少し細かく行うこと。
・他の機械学習アルゴリズムを試して、どのアルゴリズムがエロゲの価格変動に適しているか比較すること。
・学習データが不足していると思うので、学習データを増やして機械学習を行うこと。
・予測の評価を行うこと。
このあたりが今後の課題として挙げられます。
まとめ
ランダムフォレストによる機械学習でエロゲの価格変動を予測を行いました。
結果としては、外れていた部分もありますが、概ね良好な結果になったと思います。
私が予測するよりも良い精度かもしれません。
今後余裕があれば普段の更新でも、
機械学習による予測結果も紹介したいと思います。
- 関連記事
-
- 機械学習で予測するエロゲ価格変動 (答え合わせ編)
- 機械学習で予測するエロゲ価格変動 (ランダムフォレスト編)
- 評価から分析するエロゲ価格変動 第0回
- 売上ランキングから分析するエロゲ価格変動
- 移動平均から分析するエロゲ価格変動
≪ 『月光アルスマギカ』応援バナー&Twitterキャンペーン当選報告 | HOME | ExcelからjqPlotへの変換フォームを作ってみた ≫
コメントありがとうございます。
学習用データは、昨年の3月から新作エロゲの販売価格を
ゲーム博物館からクローラを使って地道に集めています。
1年以上集めてこその企画というところですね。
学習用データは、昨年の3月から新作エロゲの販売価格を
ゲーム博物館からクローラを使って地道に集めています。
1年以上集めてこその企画というところですね。
[ 2015年06月08日 22:34 ]
コメントの投稿
≪ 『月光アルスマギカ』応援バナー&Twitterキャンペーン当選報告 | HOME | ExcelからjqPlotへの変換フォームを作ってみた ≫
月別アーカイブ
カテゴリ
作品別価格情報
価格情報いろいろ
聖地巡礼・イベントなど
リンク
応援中







copyright © 2024 エロゲ価格相場を見守るブログ all rights reserved.
Benri-navi by myhurt Template by FC2ブログのテンプレート工房
Benri-navi by myhurt Template by FC2ブログのテンプレート工房
このような管理人さん独自の考察が多分に入っている記事は、読んでいて非常に興味深いです。