早速使ってみよう!
例として、アニメ
『アイドルマスターシンデレラガールズ』のストーリーに似たエロゲを探してみます。
入力するのはこちら

フォームに入力して、

「似ているエロゲを探す」ボタンを押すと・・・

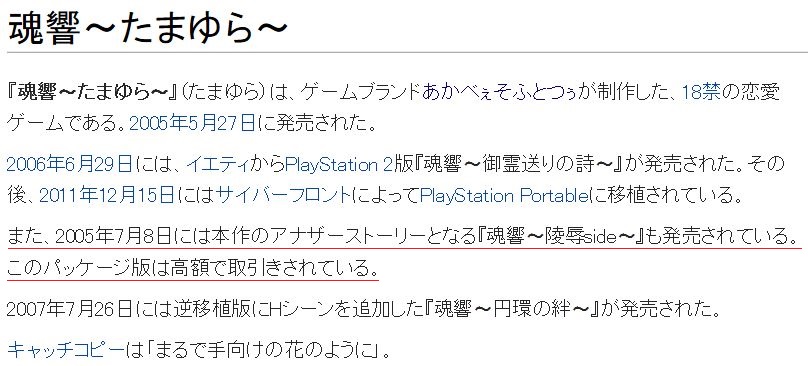
第1位から第10位までの作品名と類似度がこのように出力されます。
ちなみに1位の『studioアイドル』、2位の『D-EVE in you』、3位の『あいれぼ』は、
いずれも主人公がプロデューサーとなり、アイドルであるヒロインを攻略するといったゲーム内容です。
続いて、
「夏 田舎」というキーワード形式で入力してみましょう。

第1位から第3位までの結果がこちら。
このように夏の田舎を舞台にしたエロゲを探してくれます。
どうやって探しているのか?
さて、このサービスどういった仕組みなのかというと、
入力された文章を単語に分割し、
事前に用意したエロゲのストーリーに、それらの単語がどれだけ含まれているかを判断することで、
入力された文章と各作品のストーリーとの類似度を計算しています。そしてその類似度の高い順に出力すると。簡単に説明すると、このような感じです。
続いて、細かく説明していきたいと思います。
準備
まず比較対象として、エロゲのストーリーを大量に用意する必要があります。
各公式サイトから収集するのは非常に手間がかかる作業なので、
文字列になっていて、決まったところにストーリーの記述が存在する
Getchu.comから収集しました。
本システムには、
18禁のPCゲームのカテゴリで、ストーリーが重複していない6775作品が登録されています。
そのため、初回版と通常版がある作品でも、初回版だけが出力されるようになっています。
ちなみに6/26に収集したので、それ以降にストーリーが登録された作品については結果に出てきません。
収集した6775作品のストーリーに対して、事前処理を施します。
まずそれぞれのストーリーに対して形態素解析を行い、単語に分割します。
形態素解析というのは、自然言語処理の一種で、
文章を単語に分割し、その単語の品詞を特定する処理のことです。
例えば、
こちらの戯画の『パルフェ』のストーリーの一部を例にとって事前処理すると、以下のようになります。
事前処理の結果出力される単語は名詞、動詞、形容詞、副詞に絞っており、
動詞と形容詞については基本形に直しています。
形態素解析には
Mecabを使用しています。
類似度の計算について
類似度の計算には、入力された文章のtf-idfベクトルと、
各作品のストーリーのtf-idfベクトルから算出されるコサイン類似度を使用しています。
といっても、自然言語処理を知らない人にとっては、
なんのこっちゃわからないと思うので、一つずつ説明していきます。
・ tf-idftf-idfとは、文章中でどの単語が重要なのか、それとも重要でないのかを決めるのに使用される値です。
詳しくは
こちらに大変わかりやすい説明があるのでご覧ください。
tfは文章中における単語の出現頻度のことで、値が大きいほどその単語がよく出てきます。
式で表すと、
tf = ある単語の出現回数 / 文章全体の単語の出現回数の合計 となります。
例えば、「好き好き大好き」という文章は、
「好き」という単語が2個、「大好き」という単語が1個使用されているので、
「好き」のtfは2/3となり、「大好き」のtfは1/3となります。
idfはその単語が多くの文章の中でどれだけ共通して使われているかのことで、
値が大きいほどその単語が少ない文章でしか使われていないことを表します。
式で表すと、
idf = log ( 文書数の合計 / ある単語が出現する文書数 ) + 1 となります。
例えば、「する」という動詞は非常に多くの文章で使われているのでidfは小さく、
具体的には6775作品中、6416作品で使われており、idfは1.02となっています。
一方、「徹する」という動詞はほとんど使われていないのでidfは大きく、
具体的には6775作品中、1作品しか使われておらず、idfは4.83となっています。
そして、このtfとidfを掛け合わせたものがtf-idfです。
・ tf-idfベクトル文章をベクトル化することで、文章の方向が一意に定まり、
類似度を計算することが出来るようになります。
各単語のtf-idfをベクトルの次元とすることで、文章をベクトルにします。
ちなみに全作品のストーリーを分割した結果、合計約4万単語となったので、
4万次元のベクトルとなります。(実際はほとんどの次元が大きさ0ですが)
・ コサイン類似度コサイン類似度というのは、2つのベクトル間の角度の近さのことです。
コサイン類似度が0に近いほど、ベクトル間の角度が大きく、似ていません。
コサイン類似度が1に近いほど、ベクトル間の角度が小さく、似ています。
コサイン類似度は、2つのベクトルの内積を、2つのベクトルの絶対値の積で割ると求めることが出来ます。
この2つのベクトルに入力された文章のtf-idfベクトルと、各作品のストーリーのtf-idfベクトルを使用しています。
結果で表示されるパーセンテージは、このコサイン類似度をパーセントに直したもので、
数値の高い順に出力しています。
実装について
PHPで実装しています。せいぜい150行ぐらいですけどね。
入力された文章に対して形態素解析を行うのには
MECAPIという、MecabのWeb API版を使用しています。
ちなみに6775作品全てに対して類似度を計算しているため、
入力された文章が長いと、かなり処理時間がかかってしまいますが、
最初にコーディングした時に比べるとこれでも割とマシになった方です・・・。
一番最初は5分ぐらい時間がかかっていて、使い物にならないレベルでした。
最後に
もしPHPのエラーメッセージが表示されたり、挙動がおかしかったりした場合は、報告をお願いします。入力された文章を表示するようにはしていないので、ある程度安全だとは思いますが、
普段PHPをほとんど書かないので、バグとか脆弱性とか残ってそうでちょっと怖かったりします。
タイトルについてはとりあえずβ版としていますが、おそらく永遠にβ版のままな気がします。
それから、ご意見ご感想などありましたら、どしどしお寄せください。